Following the exploration of iGEM registry SQL dump in Querying iGEM Registry SQL Dump Intro, we explore further the sequences referenced as OmpR promoter.
select part_name, nickname from parts where nickname like"%ompr%";
Results Table
part_name
nickname
BBa_R0082
OmpR
BBa_R0083
OmpR
BBa_R0084
OmpR
BBa_I761001
OmpR_BS
BBa_K2845038
OmpR-RFFF-
BBa_K2235007
OmpR Siali
BBa_K2845032
OmpR-FFF-N
BBa_K2845037
OmpR-RFR-N
BBa_K2845008
OmpR
BBa_K2845009
OmpR
BBa_K2845035
OmpR-FFF-N
BBa_K2845040
OmpR-RFFR-
BBa_K2845041
OmpR-RFFR-
BBa_K2845042
OmpR-FFFR-
BBa_K2845044
OmpR-FRFR-
select part_name, labelfrom parts, parts_seq_features where parts.part_id = parts_seq_features.part_id and parts_seq_features.labellike"%ompr%promoter%";
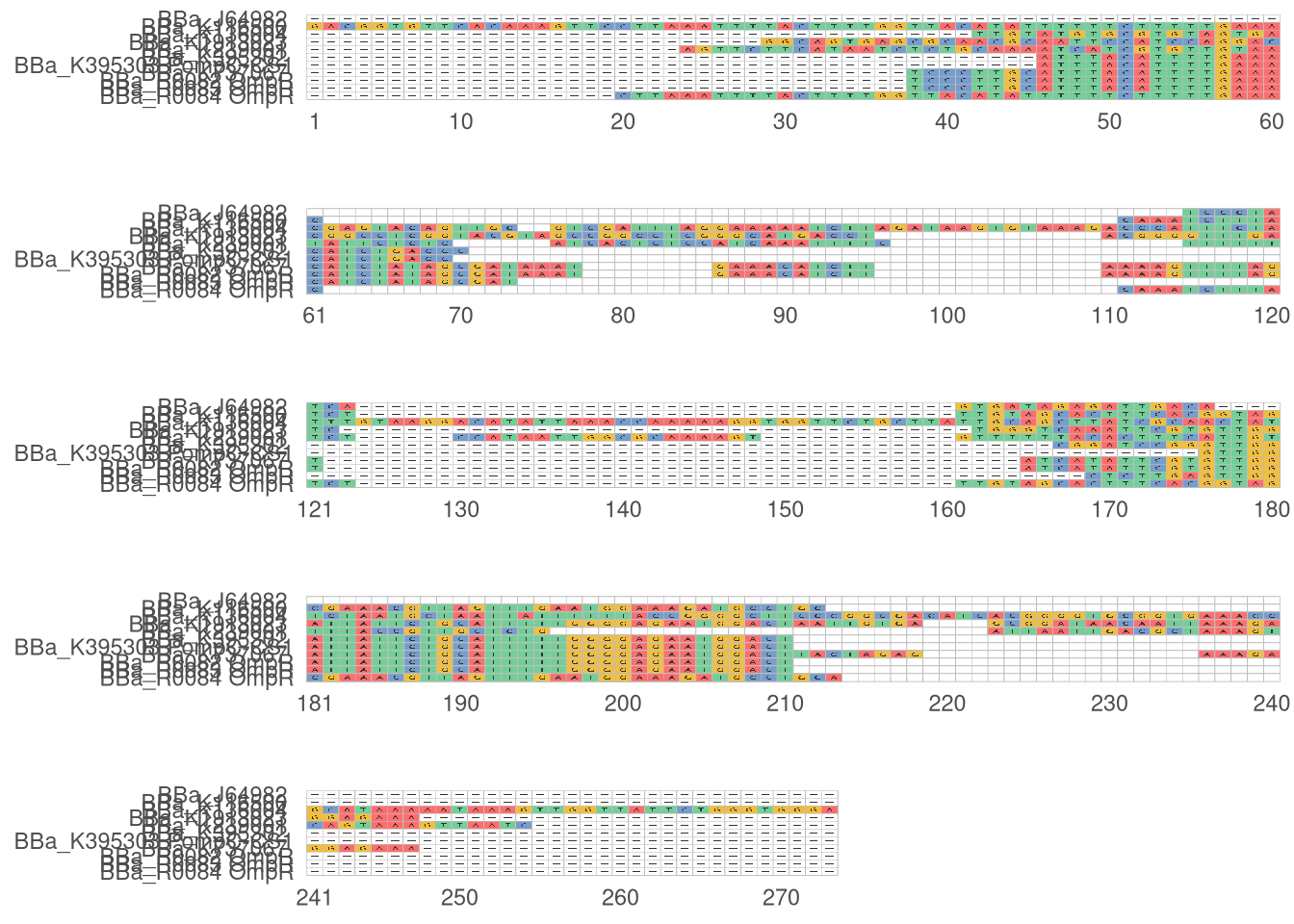
Multiple alignment of OmpR promoter binding site - Reloaded
Alignment of OmpR binding site parts
Let’s align only the pOmpR binding site having their own basic part:
select part_name, labelfrom parts, parts_seq_features where parts.part_id = parts_seq_features.part_id and parts_seq_features.labellike"%ompr%promoter%";
Results Table
part_name
label
BBa_K1766005
OmpR dependent promoter
BBa_K1766007
OmpR dependent promoter
BBa_J100314
OmpR Scrambled promoter
Gather these results:
select part_name, label, nickname from parts, parts_seq_features where parts.part_id = parts_seq_features.part_id and ( parts_seq_features.labellike"%ompr%"or parts.nickname like"%ompr%") groupby part_name orderby part_name ascinto outfile "sql_parts_like_OmpR.tsv";
Only BBa_K2235007 seems to match on the other pOmpR sequences (BBa_R0082 and BBa_R0083, not BBa_R0084).
Erratum: several OmpR labelled parts are probably the coding sequence of the protein regulatory trans element of same name. It is expected that no hit is found between these coding sequence and its DNA binding site.
Using Google Search results
Using SEOquake extension it is possible to export the google search results as a csv.
Used query:
site:parts.igem.org "ompr"
the resulting file, once extracted the urls is as follows:
To improve the reproducibility and ease the alignment, Nextflow script is written in ./workflow/musclor.nf, that goes through all steps specified in previous bash function musclor.
To run:
nextflow run ./workflow/musclor.nf --name=google_pompr_regulatory --input ./data/pOmpR/google_pompr_regulatory.fasta --outdir ./results/pOmpR/musclor
ggmsa v1.6.0 Document: http://yulab-smu.top/ggmsa/
If you use ggmsa in published research, please cite:
L Zhou, T Feng, S Xu, F Gao, TT Lam, Q Wang, T Wu, H Huang, L Zhan, L Li, Y Guan, Z Dai*, G Yu* ggmsa: a visual exploration tool for multiple sequence alignment and associated data. Briefings in Bioinformatics. DOI:10.1093/bib/bbac222
Scale for x is already present.
Adding another scale for x, which will replace the existing scale.
Coordinate system already present. Adding new coordinate system, which will
replace the existing one.